- 원문은 Anthropic의 원 글을 확인해주세요.
에이전트 코딩의 최전선에서 성능을 좌우하는 핵심 요소 중 하나가 harness 설계입니다. 이 글에서는 Claude를 프런트엔드 디자인과 장시간 자율 소프트웨어 엔지니어링에서 더 멀리 밀어붙이기 위해 Anthropic이 어떤 시도를 했는지 설명합니다.
이 글은 Anthropic Labs 팀의 Prithvi Rajasekaran이 작성했습니다.
지난 몇 달 동안 저는 서로 맞물린 두 가지 문제를 다뤄왔습니다. 하나는 Claude가 고품질 프런트엔드 디자인을 만들게 하는 일이고, 다른 하나는 사람 개입 없이 완전한 애플리케이션을 구축하게 하는 일입니다. 이 작업은 이전에 진행했던 frontend design skill과 long-running coding agent harness 작업1에서 출발했습니다. 동료들과 저는 프롬프트 엔지니어링과 harness 설계를 통해 Claude 성능을 기준선보다 훨씬 끌어올렸지만, 두 접근 모두 결국에는 한계에 부딪혔습니다.
돌파구를 찾기 위해 저는 성격이 꽤 다른 두 영역, 즉 주관적 취향이 중요한 영역과 검증 가능한 정확성 및 사용성이 중요한 영역 모두에 통하는 새로운 AI 엔지니어링 접근을 찾았습니다. Generative Adversarial Networks (GANs)에서 영감을 얻어 generator agent와 evaluator agent로 구성된 멀티 에이전트 구조를 설계했습니다. 출력물을 신뢰할 수 있게, 그리고 어느 정도의 미감까지 반영해 채점하는 evaluator를 만들려면 먼저 "이 디자인이 좋은가?" 같은 주관적 판단을 구체적으로 채점 가능한 기준으로 바꾸는 작업이 필요했습니다.
이후 이 기법을 장시간 자율 코딩에 적용했습니다. 여기에는 이전 harness 작업에서 얻은 두 가지 교훈, 즉 빌드를 다룰 만한 크기의 조각으로 쪼개는 일과 세션 사이에 context를 넘기기 위해 구조화된 산출물을 쓰는 일을 그대로 가져왔습니다. 최종 결과는 planner, generator, evaluator로 이루어진 3-agent 아키텍처였고, 이 구조는 여러 시간에 걸친 자율 코딩 세션에서 풍부한 full-stack 애플리케이션을 만들어냈습니다.
Why naive implementations fall short
Anthropic은 이전에도 harness 설계가 장시간 실행되는 에이전트 코딩의 효과를 크게 좌우한다는 점을 보여준 적이 있습니다. 앞선 실험1에서는 initializer agent가 제품 명세를 작업 목록으로 분해하고, coding agent가 한 번에 하나의 기능을 구현한 뒤 세션 사이에 context를 넘길 산출물을 남기도록 했습니다. 더 넓은 개발자 커뮤니티도 비슷한 통찰에 수렴해왔고, 예를 들어 hook이나 script를 써서 agent를 계속 반복 루프에 묶어두는 "Ralph Wiggum" 같은 접근도 등장했습니다.
하지만 몇몇 문제는 계속 남아 있었습니다. 더 복잡한 작업일수록 agent는 시간이 지나며 여전히 궤도를 이탈하는 경향이 있었습니다. 이 문제를 분해해보는 과정에서, 이런 종류의 작업을 수행하는 agent에게서 공통적으로 나타나는 두 가지 실패 모드를 관찰했습니다.
첫 번째는 긴 작업을 진행하면서 context window가 차오를수록 모델이 일관성을 잃는다는 점입니다. 자세한 내용은 context engineering 글2에서 다뤘습니다. 일부 모델은 "context anxiety"도 보였는데, 자신이 생각하는 context 한계에 가까워질수록 작업을 너무 일찍 마무리하려는 경향입니다. context window를 완전히 비우고 새 agent를 시작하되, 이전 agent의 상태와 다음 단계가 담긴 구조화된 handoff를 함께 넘기는 context reset은 이 두 문제를 동시에 해결해줍니다.
이 방식은 compaction과는 다릅니다. compaction은 대화의 앞부분을 제자리에서 요약해 같은 agent가 더 짧아진 history를 바탕으로 계속 일하게 만드는 방법입니다. compaction은 연속성을 보존하지만, agent에게 깨끗한 출발점을 주지는 못합니다. 그래서 context anxiety가 계속 남을 수 있습니다. 반면 reset은 깨끗한 출발점을 주는 대신, 다음 agent가 작업을 무리 없이 이어받을 만큼 충분한 상태 정보가 handoff 산출물에 담겨 있어야 합니다. 이전 실험에서 Anthropic은 Claude Sonnet 4.5가 context anxiety를 꽤 강하게 보여, compaction만으로는 장기 작업 성능을 충분히 끌어낼 수 없다는 점을 확인했습니다. 그래서 context reset이 harness 설계의 필수 요소가 됐습니다. 이 방식은 핵심 문제는 해결하지만, 그 대신 오케스트레이션 복잡도와 토큰 오버헤드, 그리고 실행 지연이 늘어납니다.
두 번째 문제는 Anthropic이 이전에는 본격적으로 다루지 않았던 self-evaluation입니다. agent에게 자신이 만든 결과물을 평가하라고 하면, 사람 눈에는 품질이 뻔히 평범해 보여도 자신 있게 칭찬하는 쪽으로 기웁니다. 이 문제는 특히 디자인처럼 주관적 판단이 필요한 작업에서 두드러집니다. 검증 가능한 소프트웨어 테스트처럼 이진적으로 통과 여부를 판정할 수 있는 장치가 없기 때문입니다. 레이아웃이 세련됐는지, 아니면 그저 흔한지 여부는 결국 판단의 문제인데, agent는 자기 작업을 채점할 때 일관되게 후한 점수를 줍니다.
물론 검증 가능한 결과가 있는 작업에서도 agent는 일을 수행하는 과정에서 성능을 떨어뜨리는 나쁜 판단을 종종 내립니다. 실제 작업을 수행하는 agent와 그것을 평가하는 agent를 분리하는 것은 이 문제를 다루는 강력한 레버였습니다. 분리만으로 그 관대함이 즉시 사라지지는 않습니다. evaluator 역시 LLM이고, LLM이 만든 산출물에 관대해지기 쉽기 때문입니다. 하지만 독립된 evaluator를 회의적으로 채점하도록 튜닝하는 일은 generator가 자기 작업을 비판적으로 보게 만드는 일보다 훨씬 다루기 쉬웠고, 일단 외부 피드백이 생기면 generator는 그 피드백을 기준으로 구체적으로 반복 개선할 수 있게 됩니다.
Frontend design: making subjective quality gradable
저는 self-evaluation 문제가 가장 눈에 띄게 드러나는 프런트엔드 디자인부터 실험을 시작했습니다. 별다른 개입이 없으면 Claude는 기술적으로는 동작하지만 시각적으로는 특별할 것 없는, 안전하고 예측 가능한 레이아웃 쪽으로 자연스럽게 수렴했습니다.
프런트엔드 디자인용 harness를 만들 때 두 가지 통찰이 방향을 정했습니다. 첫째, 미감은 점수 하나로 완전히 환원할 수 없고 사람마다 취향도 다르지만, 디자인 원칙과 선호를 담은 grading criterion을 만들면 분명히 개선할 수 있다는 점입니다. "이 디자인이 아름다운가?"는 일관되게 답하기 어렵지만, "이 디자인이 우리가 생각하는 좋은 디자인 원칙을 따르는가?"는 Claude가 구체적으로 채점할 기준이 됩니다. 둘째, 프런트엔드 생성과 프런트엔드 평가를 분리하면 generator를 더 강한 결과물 쪽으로 밀어주는 피드백 루프를 만들 수 있다는 점입니다.
이 생각을 바탕으로 저는 generator와 evaluator agent 둘 다의 prompt에 아래 네 가지 grading criterion을 넣었습니다.
- Design quality: 디자인이 조각들의 나열이 아니라 하나의 일관된 전체처럼 느껴지는가? 여기서 높은 점수를 받으려면 색상, 타이포그래피, 레이아웃, 이미지, 세부 요소가 함께 작동해 분명한 분위기와 정체성을 만들어야 합니다.
- Originality: 맞춤형 의사결정의 흔적이 있는가, 아니면 템플릿 레이아웃, 라이브러리 기본값, AI가 자주 만드는 패턴에 기대고 있는가? 인간 디자이너가 봐도 의도적인 창의적 선택이 보이는 수준이어야 합니다. 손대지 않은 기본 제공 컴포넌트나, 흰 카드 위에 보라색 그라디언트를 얹는 식의 전형적인 AI 생성 흔적은 여기서 탈락합니다.
- Craft: 기술적 완성도입니다. 타이포그래피 위계, 간격의 일관성, 색상 조화, 대비 비율 같은 요소를 봅니다. 창의성보다 숙련도를 점검하는 항목에 가깝습니다. 대부분의 무난한 구현은 기본적으로 여기서는 잘 나오며, 실패한다면 기초가 무너진 경우입니다.
- Functionality: 미감과 별개로 사용성이 확보됐는가를 봅니다. 사용자가 인터페이스가 무엇을 하는지 이해하고, 핵심 액션을 찾고, 추측하지 않고도 작업을 끝낼 수 있는가를 묻습니다.
저는 craft와 functionality보다 design quality와 originality에 더 큰 비중을 뒀습니다. Claude는 원래도 필요한 기술적 완성도를 자연스럽게 갖추는 편이라 craft와 functionality에서는 기본 점수가 높았습니다. 하지만 디자인과 독창성 측면에서는 많아야 밋밋한 수준의 결과물을 내놓는 경우가 잦았습니다. 이 기준은 지나치게 전형적인 "AI slop" 패턴에 명시적으로 불이익을 주었고, 디자인과 독창성에 더 높은 가중치를 주면서 모델이 미적으로 더 과감한 선택을 하게 만들었습니다.
저는 세부적인 점수 분해가 담긴 few-shot 예시로 evaluator를 보정했습니다. 이 덕분에 evaluator의 판단이 제 선호와 더 잘 맞아떨어졌고, 반복이 진행될수록 점수가 흔들리는 현상도 줄어들었습니다.
루프는 Claude Agent SDK 위에 구축했습니다. 덕분에 오케스트레이션은 비교적 단순하게 유지할 수 있었습니다. 먼저 generator agent가 사용자 프롬프트를 바탕으로 HTML/CSS/JS 프런트엔드를 만들고, evaluator에는 Playwright MCP를 제공해 실제 살아 있는 페이지를 직접 조작하면서 각 기준을 채점하고 상세한 평가 의견을 작성하게 했습니다. 실제로 evaluator는 스스로 페이지를 돌아다니며 스크린샷을 찍고 구현을 세심하게 살핀 뒤 평가를 내렸습니다. 이 피드백은 다음 반복의 입력으로 다시 generator에게 돌아갔습니다. 저는 한 번의 생성에 5회에서 15회 정도의 반복을 돌렸고, 보통은 반복이 거듭될수록 evaluator의 평가 의견에 반응하면서 generator가 더 뚜렷한 방향으로 밀려갔습니다. evaluator가 정적 스크린샷이 아니라 페이지를 직접 탐색했기 때문에 각 사이클에는 실제 경과 시간이 필요했고, 전체 실행 시간은 최대 4시간까지 늘어났습니다. 또 저는 generator가 매 평가 뒤 전략적 결정을 내리도록 했습니다. 점수가 좋게 흐르면 현재 방향을 더 다듬고, 접근이 잘 안 풀리면 완전히 다른 미감 방향으로 피벗하라는 식입니다.
실험을 거듭할수록 evaluator의 평가는 반복이 진행되면서 좋아지다가 어느 시점에서 plateau에 도달했습니다. 그래도 더 끌어올릴 여지는 남아 있었습니다. 어떤 생성물은 점진적으로 정제됐고, 어떤 생성물은 반복 사이에 미감 방향이 크게 꺾이기도 했습니다.
criterion의 문구는 제가 완전히 예상하지 못한 방식으로 generator를 유도하기도 했습니다. 예를 들어 "the best designs are museum quality" 같은 문구를 넣자 디자인이 특정한 시각적 수렴점 쪽으로 움직였습니다. 즉, criterion에 붙은 prompt 문구 자체가 결과물의 성격을 직접 형성하고 있다는 뜻입니다.
점수는 대체로 반복이 진행될수록 올라갔지만, 패턴이 언제나 깔끔한 선형은 아니었습니다. 전체적으로는 뒤 반복의 구현이 더 나은 경우가 많았지만, 실제로는 마지막 결과보다 중간 반복을 더 선호한 사례도 자주 있었습니다. 구현 복잡도 역시 라운드가 갈수록 커지는 경향이 있었고, generator는 evaluator 피드백에 반응해 더 야심찬 해법을 시도했습니다. 흥미로운 점은 첫 반복만 봐도 아무 프롬프트를 넣지 않은 기준선보다 결과가 확실히 낫다는 점이었습니다. evaluator 피드백이 들어가기 전부터, criterion과 거기에 딸린 언어 자체가 모델을 전형적인 기본값에서 멀어지게 만들고 있었던 셈입니다.
특히 기억에 남는 사례로, 저는 모델에게 네덜란드 미술관 웹사이트를 만들라고 요청했습니다. 9번째 반복까지는 가상의 미술관을 위한 깔끔한 다크 테마 랜딩 페이지가 나왔습니다. 시각적으로는 잘 다듬어졌지만 대체로 제 예상 범위 안에 있었습니다. 그런데 10번째 사이클에서 모델은 그 접근을 완전히 버리고 사이트를 공간적 경험으로 다시 상상했습니다. CSS perspective로 렌더링한 체커보드 바닥의 3D 방을 만들고, 작품을 벽면에 자유로운 위치로 걸어두고, 스크롤이나 클릭 대신 문을 통해 갤러리 방을 오가게 했습니다. 단일 패스 생성에서는 이전까지 거의 보지 못했던 수준의 창의적 도약이었습니다.
Scaling to full-stack coding
이런 결과를 바탕으로 저는 이 GAN에서 착안한 패턴을 풀스택 개발로 확장했습니다. generator-evaluator 루프는 소프트웨어 개발 생명주기에 자연스럽게 대응됩니다. 코드 리뷰와 QA가 구조적으로는 디자인 evaluator와 같은 역할을 하기 때문입니다.
The architecture
이전 long-running harness1에서는 initializer agent, 한 번에 하나의 기능만 처리하는 coding agent, 그리고 세션 사이의 context reset을 조합해 여러 세션에 걸친 코딩 일관성을 확보했습니다. context reset은 핵심적인 전환점이었습니다. 당시 harness는 Sonnet 4.5를 사용했고, 앞서 말한 "context anxiety" 성향을 보였기 때문입니다. context reset이 있어야 모델이 작업에 계속 집중할 수 있었습니다. 그런데 Opus 4.5에서는 그런 행동이 상당 부분 사라져, 이번 harness에서는 context reset을 완전히 제거할 수 있었습니다. agent들은 빌드 전체를 하나의 연속 세션으로 수행했고, Claude Agent SDK의 자동 compaction이 그 과정에서 늘어나는 context를 관리했습니다.
이번 작업에서는 원래 harness의 토대 위에 3-agent 시스템을 쌓았고, 각 agent는 이전 실행에서 보였던 특정한 공백을 메우도록 설계했습니다. 시스템에는 아래 세 가지 agent persona가 있었습니다.
Planner: 이전 long-running harness에서는 사용자가 처음부터 자세한 명세를 제공해야 했습니다. 저는 이 단계를 자동화하고 싶어서, 1-4문장짜리 간단한 프롬프트를 완전한 제품 명세로 확장하는 planner agent를 만들었습니다. planner에게는 범위를 야심차게 잡되, 세부 구현보다는 제품 맥락과 고수준 기술 설계에 집중하라고 지시했습니다. planner가 처음부터 세밀한 기술 디테일까지 못 박다가 틀리면, 그 오류가 이후 구현 전체로 연쇄 전파될 수 있다는 우려 때문입니다. 차라리 agent를 산출물에 맞춰 제약하고, 실제 경로는 일하면서 찾아가게 하는 편이 더 똑똑하다고 판단했습니다. 또 planner에게 제품 명세 안에 AI 기능을 자연스럽게 끼워 넣을 기회를 찾으라고 했습니다. 맨 아래 Appendix에 예시가 있습니다.
Generator: 이전 harness에서 한 번에 하나의 기능만 구현하는 방식은 범위 관리에 꽤 효과적이었습니다. 여기서도 비슷한 모델을 적용해, generator가 명세에서 한 번에 하나의 기능을 집어 들고 sprint 단위로 일하게 했습니다. 각 sprint는 React, Vite, FastAPI, SQLite(이후 PostgreSQL) 스택으로 앱을 구현했고, generator는 각 sprint 말미에 스스로 작업을 평가한 뒤 QA로 넘기도록 지시받았습니다. 버전 관리를 위한 git도 사용할 수 있었습니다.
Evaluator: 이전 harness에서 나온 애플리케이션은 겉보기에는 인상적이어도 실제로 써보면 버그가 있는 경우가 많았습니다. 이를 잡아내기 위해 evaluator는 Playwright MCP를 사용해, 사용자가 하듯 실행 중인 애플리케이션을 직접 클릭하며 UI 기능, API endpoint, 데이터베이스 상태를 테스트했습니다. 이후 evaluator는 자신이 발견한 버그와, 프런트엔드 실험에서 가져와 제품 깊이, 기능성, 시각적 디자인, 코드 품질을 포괄하도록 조정한 기준을 바탕으로 각 sprint를 채점했습니다. 각 criterion에는 명확한 임계값이 있었고, 하나라도 기준을 밑돌면 sprint는 실패 처리됐으며 generator는 무엇이 잘못됐는지에 대한 상세 피드백을 받았습니다.
sprint마다 generator와 evaluator는 먼저 sprint contract를 협상했습니다. 즉, 코드를 쓰기 전에 이 작업 덩어리에서 무엇이 done인지 합의한 것입니다. 제품 명세는 의도적으로 고수준에 머물렀기 때문에, 저는 사용자 스토리와 테스트 가능한 구현 사이를 잇는 중간 단계가 필요하다고 봤습니다. generator는 무엇을 만들고 어떤 방식으로 성공을 검증할지 제안하고, evaluator는 그 제안이 정말 올바른 대상을 만들고 있는지 검토했습니다. 둘은 합의에 이를 때까지 반복했습니다.
커뮤니케이션은 파일로 이뤄졌습니다. 한 agent가 파일을 쓰면, 다른 agent가 그 파일을 읽고 같은 파일 안에 응답하거나 새로운 파일을 작성해 다시 넘기는 식입니다. 이후 generator는 합의된 contract에 맞춰 구현한 뒤 QA로 넘겼습니다. 이 방식 덕분에 너무 이른 시점에 구현을 과도하게 고정하지 않으면서도, 작업이 spec에 충실하게 유지됐습니다.
Running the harness
이 harness의 첫 버전에서는 Claude Opus 4.5를 사용했고, 같은 사용자 프롬프트를 full harness와 single-agent 시스템 양쪽에 넣어 비교했습니다. 이 실험을 시작할 당시 Opus 4.5가 Anthropic의 최고 코딩 모델이었기 때문입니다.
레트로 비디오 게임 메이커를 만들기 위해 저는 아래와 같은 프롬프트를 썼습니다.
Create a 2D retro game maker with features including a level editor, sprite editor, entity behaviors, and a playable test mode.
아래 표는 harness 유형, 실행 시간, 총비용을 보여줍니다.
| Harness | Duration | Cost |
|---|---|---|
| Solo | 20 min | $9 |
| Full harness | 6 hr | $200 |
harness 쪽이 20배 넘게 비쌌지만, 결과물 품질의 차이는 즉시 드러났습니다.
제가 기대한 것은 레벨과 그 구성 요소(스프라이트, 엔티티, 타일 배치)를 만든 뒤 곧바로 플레이를 눌러 실제로 레벨을 플레이할 수 있는 인터페이스였습니다. 먼저 solo run 결과물을 열어봤는데, 초기 애플리케이션은 그런 기대에 어느 정도 부합해 보였습니다.
하지만 여기저기 클릭해보기 시작하자 문제가 드러났습니다. 고정 높이 패널이 대부분의 뷰포트를 비워 둔 채 공간을 낭비했고, 워크플로도 경직돼 있었습니다. 레벨을 채워 넣으려 하면 먼저 스프라이트와 엔티티를 만들라는 흐름으로 몰아가지만, UI 어디에도 그 순서를 안내하는 장치가 없었습니다. 무엇보다 실제 게임이 망가져 있었습니다. 엔티티는 화면에 나타나지만 입력에 아무 반응도 하지 않았습니다. 코드를 파보니 엔티티 정의와 게임 런타임 사이 연결이 깨져 있었고, 겉으로는 어디가 문제인지 드러나지 않았습니다.
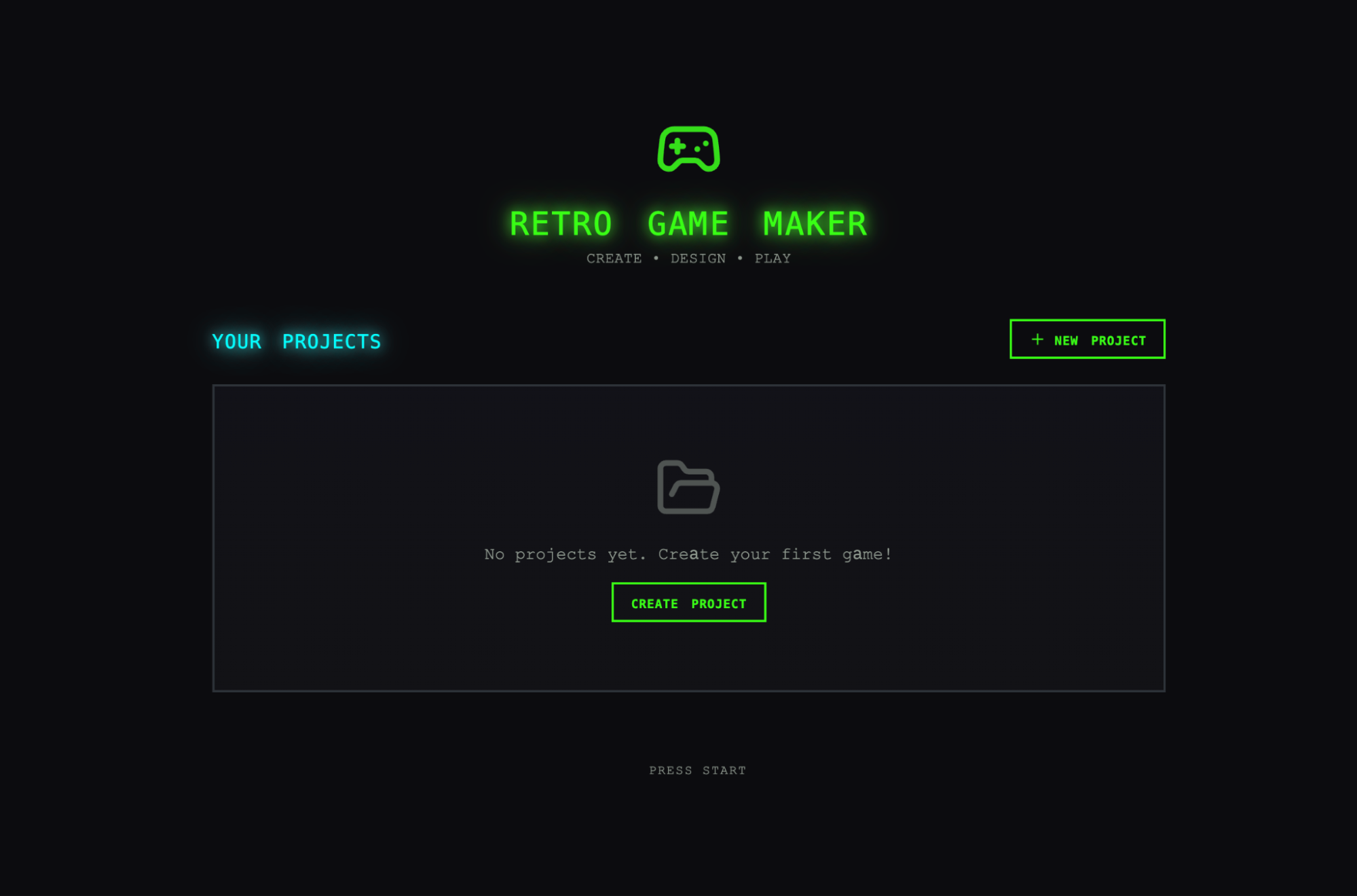
solo harness가 만든 앱을 처음 열었을 때의 초기 화면입니다.

solo harness가 만든 스프라이트 에디터에서 스프라이트를 만드는 모습입니다.
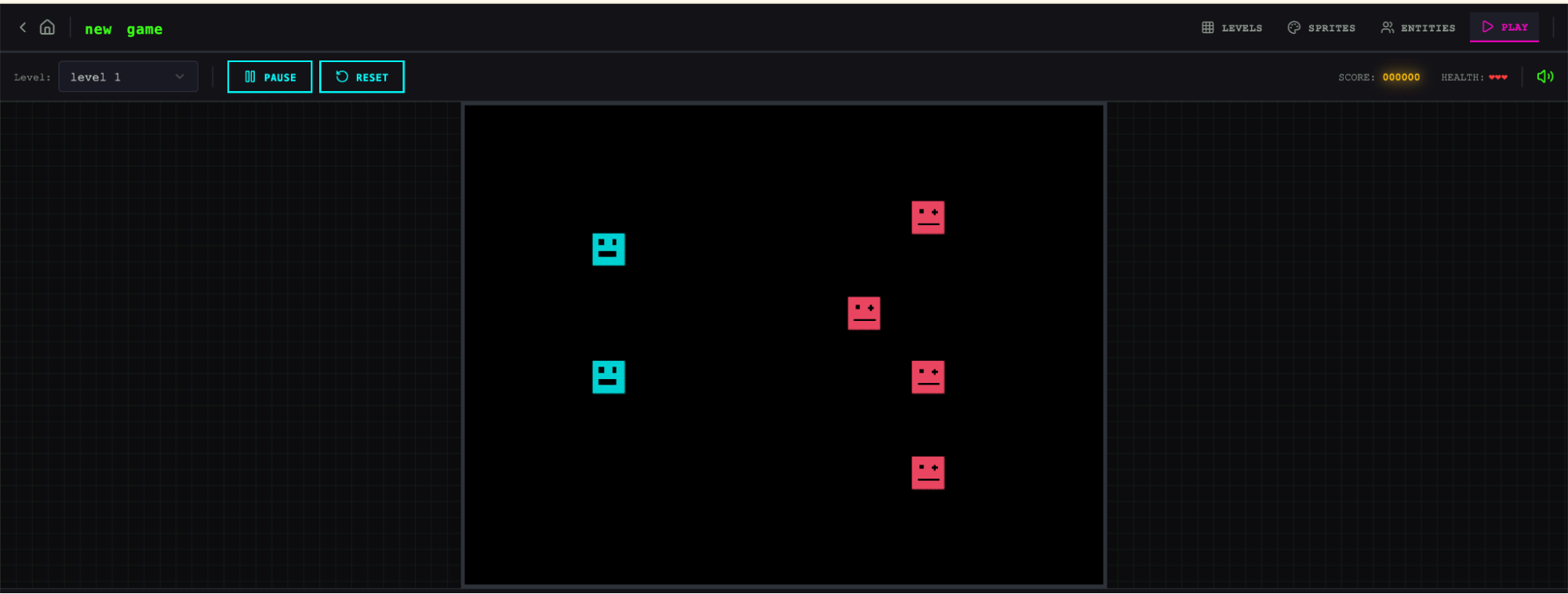
제가 만든 레벨을 플레이해보려 했지만 제대로 동작하지 않았습니다.
solo run을 평가한 뒤 저는 harness run으로 시선을 돌렸습니다. 이 실행은 같은 한 문장 프롬프트에서 시작했지만, planner 단계가 이를 10개 sprint에 걸친 16개 기능 명세로 확장했습니다. solo run이 시도한 것보다 훨씬 많은 내용을 담고 있었습니다. 핵심 에디터와 플레이 모드 외에도 스프라이트 애니메이션 시스템, 행동 템플릿, 효과음과 음악, AI 보조 스프라이트 생성기와 레벨 디자이너, 그리고 공유 링크가 있는 게임 내보내기 기능까지 포함돼 있었습니다. 저는 planner에게 frontend design skill도 읽게 했고, planner는 이를 활용해 명세의 일부로 앱의 시각 디자인 언어까지 만들어냈습니다. sprint마다 generator와 evaluator는 그 sprint에서 구현할 구체 사항과 완료 여부를 검증할 테스트 가능한 행동을 정의하는 contract를 협상했습니다.
앱은 처음부터 solo run보다 더 매끄럽고 정돈돼 보였습니다. 캔버스는 뷰포트를 가득 사용했고, 패널 크기도 합리적이었으며, 인터페이스에는 명세의 디자인 방향을 따라가는 일관된 시각 정체성이 있었습니다. solo run에서 봤던 어색함이 완전히 사라진 것은 아니었습니다. 여전히 스프라이트와 엔티티를 먼저 만든 다음 레벨을 채워야 한다는 점이 워크플로에 분명히 드러나지 않았고, 저는 직접 만져보면서 그 사실을 알아내야 했습니다. 다만 이건 harness가 해결하도록 설계된 문제라기보다 기본 모델의 제품 감각이 비는 지점으로 읽혔습니다. 동시에 harness 내부에서 목표를 더 정밀하게 반복 개선하면 출력 품질을 한 단계 더 올릴 수 있겠다는 힌트도 줬습니다.
에디터를 더 둘러볼수록 새 run이 solo보다 우월한 지점은 더 분명해졌습니다. 스프라이트 에디터는 훨씬 풍부하고 완성도가 높았고, 도구 팔레트는 더 깔끔했으며, 색상 선택기와 확대 제어도 더 쓰기 좋았습니다.
또 planner에게 명세 안에 AI 기능을 녹여 넣으라고 했기 때문에, 이 앱에는 프롬프트만으로 게임의 여러 부분을 생성할 수 있는 Claude 통합 기능도 기본 제공됐습니다. 이 덕분에 작업 흐름은 눈에 띄게 빨라졌습니다.
full harness로 만든 앱에서 새 게임을 만드는 초기 화면입니다.
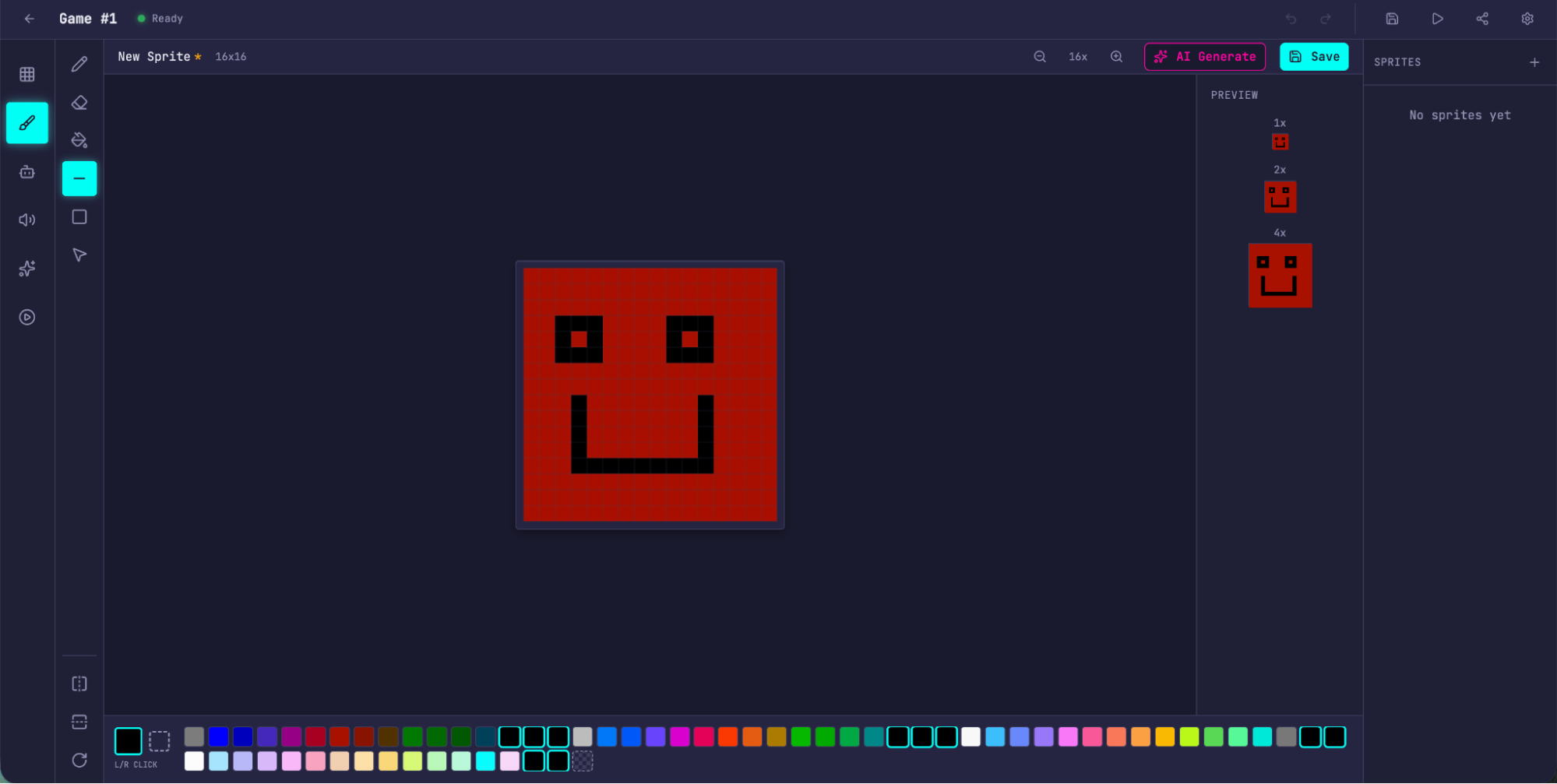
스프라이트 에디터가 더 깔끔하고 쓰기 쉬워졌습니다.
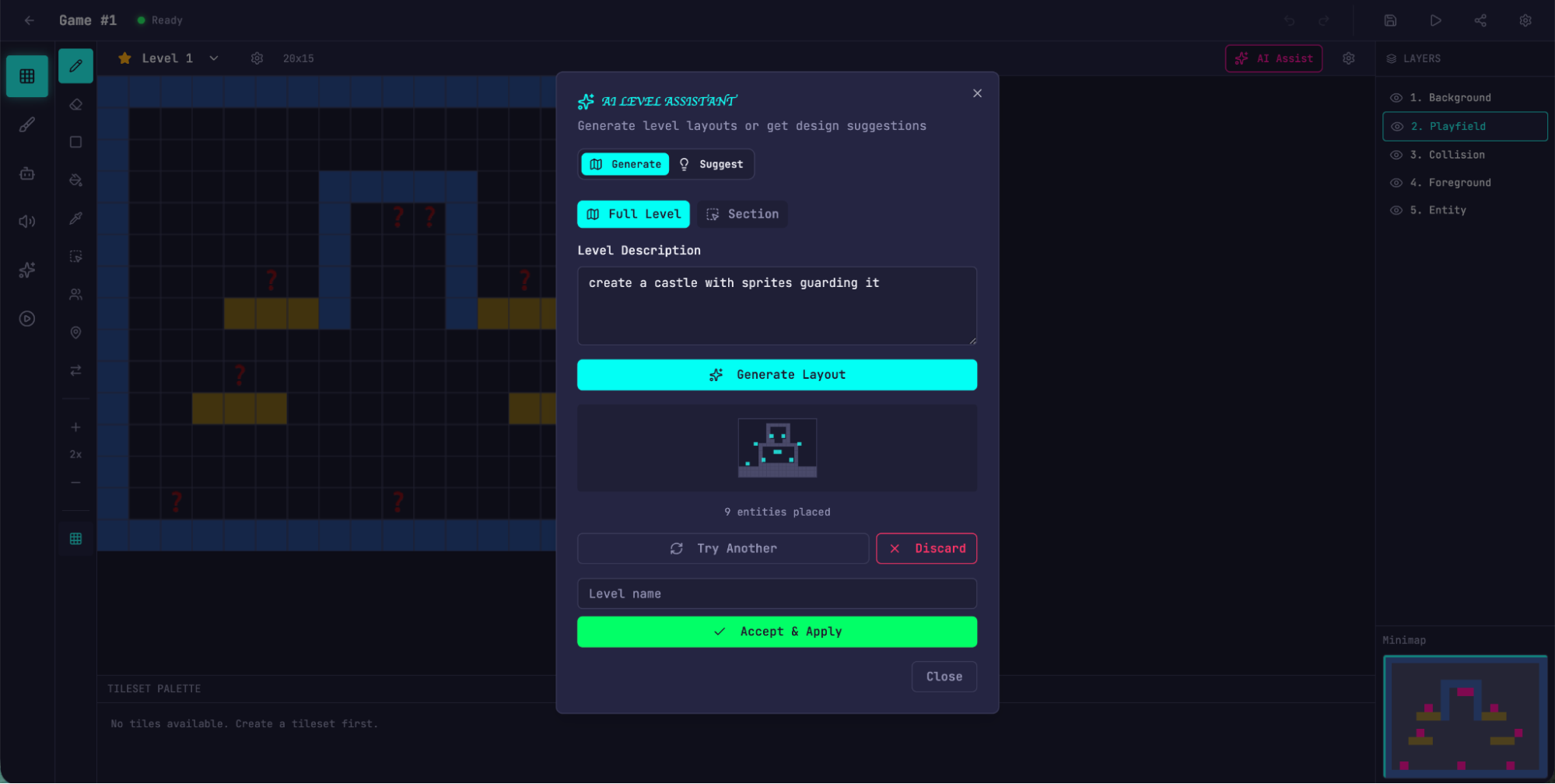
내장된 AI 기능으로 레벨을 생성하는 모습입니다.
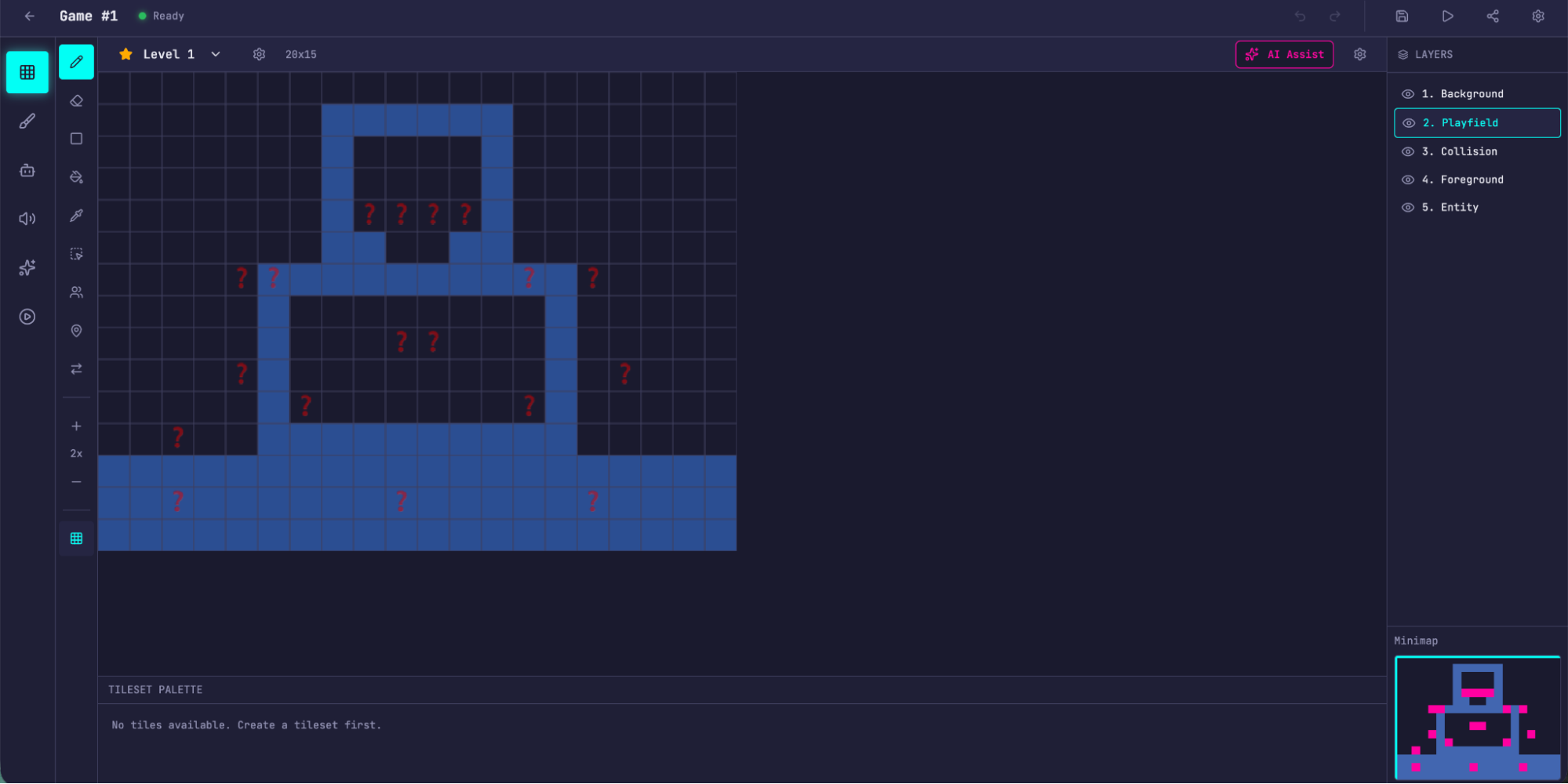
내장된 AI 기능으로 레벨을 생성하는 또 다른 장면입니다.
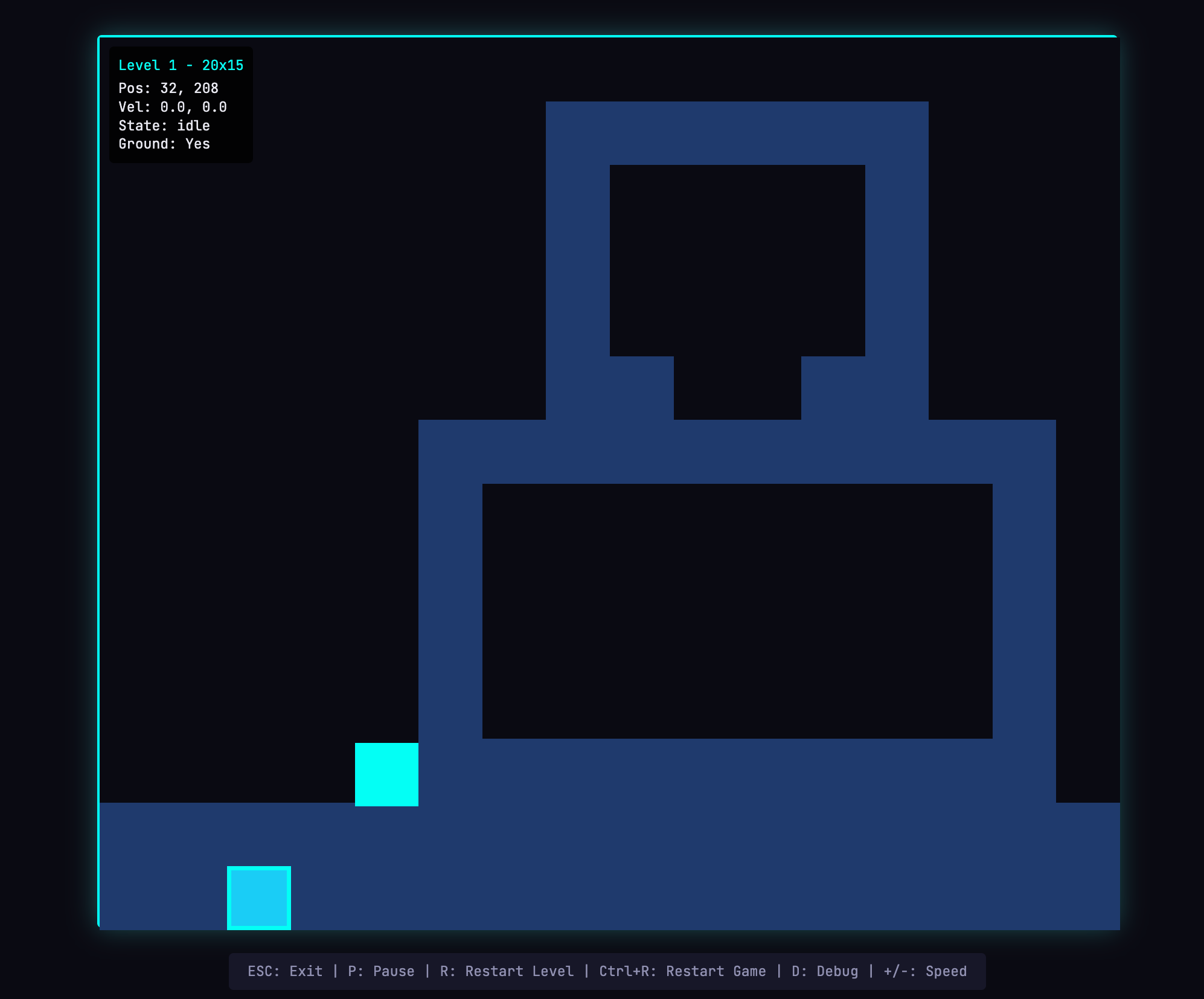
제가 생성한 게임을 실제로 플레이하는 모습입니다.
가장 큰 차이는 플레이 모드에서 드러났습니다. 저는 실제로 엔티티를 움직이며 게임을 플레이할 수 있었습니다. 물론 물리 구현에는 거친 부분이 있었습니다. 캐릭터가 플랫폼 위로 점프한 뒤 플랫폼과 겹쳐버려 직관적으로 어색하게 느껴졌습니다. 하지만 핵심 기능 자체는 동작했습니다. solo run은 끝내 해내지 못한 부분입니다. 조금 더 움직여보자 AI가 구성한 게임 레벨에는 한계도 보였습니다. 뛰어넘을 수 없는 큰 벽이 있어서 진행이 막혔습니다. 이런 점은 harness가 상식적인 개선과 예외 사례 처리를 더 잘 다루도록 발전하면 앱 품질을 추가로 높일 수 있음을 시사했습니다.
로그를 읽어보면 evaluator가 구현을 명세에 맞춰 단단히 붙들고 있었음이 분명했습니다. sprint마다 evaluator는 sprint contract의 테스트 기준을 하나씩 따라가며 Playwright로 실행 중인 애플리케이션을 실제로 조작했고, 기대 동작과 어긋나는 부분에는 모두 버그를 등록했습니다. contract는 매우 세밀했습니다. Sprint 3 하나만 봐도 레벨 에디터에 대한 기준이 27개였습니다. 그리고 evaluator가 남긴 결과는 추가 조사 없이도 바로 조치할 수 있을 만큼 구체적이었습니다. 아래 표는 evaluator가 찾아낸 문제의 일부 예시입니다.
| Contract criterion | Evaluator finding |
|---|---|
직사각형 채우기 도구는 선택한 타일로 영역을 click-drag해 채울 수 있어야 한다. |
FAIL - 도구가 영역을 채우지 않고 drag 시작점과 끝점에만 타일을 놓습니다. fillRectangle 함수는 존재하지만 mouseUp에서 제대로 호출되지 않습니다. |
| 사용자는 배치한 엔티티 스폰 지점을 선택하고 삭제할 수 있어야 한다. | FAIL - LevelEditor.tsx:892의 Delete 키 핸들러는 selection과 selectedEntityId가 모두 설정돼 있어야만 동작하지만, 엔티티를 클릭하면 selectedEntityId만 설정됩니다. 조건은 selection || (selectedEntityId && activeLayer === 'entity')여야 합니다. |
| 사용자는 API를 통해 애니메이션 프레임 순서를 재정렬할 수 있어야 한다. | FAIL - PUT /frames/reorder 라우트가 /{frame_id} 라우트 뒤에 정의돼 있습니다. 그래서 FastAPI가 reorder를 정수형 frame_id로 해석해 422 "unable to parse string as an integer."를 반환합니다. |
evaluator를 이 정도 수준까지 끌어올리는 데도 적지 않은 작업이 필요했습니다. 기본 상태의 Claude는 좋은 QA agent가 아닙니다. 초기 실행에서는 실제 문제를 발견해놓고도, 스스로 "이 정도면 큰 문제는 아니다"라고 설득한 뒤 작업을 통과시켜 버리는 모습을 자주 봤습니다. 또 예외 사례를 집요하게 파기보다는 피상적으로 테스트하는 경향이 있어, 더 미묘한 버그가 쉽게 빠져나갔습니다. 튜닝 루프는 evaluator 로그를 읽고, 제 판단과 evaluator 판단이 어긋난 사례를 찾고, 그런 문제를 해결하도록 QA 프롬프트를 갱신하는 식이었습니다. evaluator의 채점이 제가 보기에 충분히 합리적이라고 느껴질 때까지 이 개발 루프를 여러 차례 반복해야 했습니다. 그래도 harness 결과물은 모델 QA 능력의 한계를 보여줬습니다. 사소한 레이아웃 문제, 어딘가 직관적이지 않은 상호작용, evaluator가 깊게 건드려보지 않아 발견하지 못한 더 깊은 기능의 버그가 남아 있었습니다. 추가 튜닝으로 끌어낼 검증 여지는 분명히 더 있었습니다. 그럼에도 애플리케이션의 중심 기능 자체가 작동하지 않았던 solo run과 비교하면, 개선 폭은 명백했습니다.
Iterating on the harness
첫 번째 harness 결과는 고무적이었지만, 동시에 무겁고 느리고 비쌌습니다. 다음 단계는 성능을 떨어뜨리지 않으면서 harness를 단순화할 방법을 찾는 일이었습니다. 이 판단에는 상식적인 이유도 있었고, 더 일반적인 원칙도 작용했습니다. harness 안의 모든 구성요소는 "현재 모델이 혼자서는 못 하는 것"에 대한 가정을 담고 있는데, 이런 가정은 틀렸을 수도 있고, 모델이 발전할수록 빠르게 낡을 수도 있기 때문에 반드시 스트레스 테스트해볼 가치가 있습니다. Anthropic의 Building Effective Agents 글은 이 아이디어를 "가능한 가장 단순한 해법을 먼저 찾고, 필요할 때만 복잡성을 늘려라"라고 설명합니다. agent harness를 유지보수하는 사람이라면 누구나 반복적으로 마주치게 되는 패턴입니다.
처음 단순화를 시도했을 때 저는 harness를 과감하게 덜어내고 몇 가지 새로운 아이디어도 실험했지만, 원래 성능을 재현하지는 못했습니다. 동시에 어떤 조각이 실제로 중요한 하중을 지탱하고 있었는지, 그리고 그 이유가 무엇인지 파악하기도 어려워졌습니다. 이 경험 이후 저는 더 체계적인 접근으로 방향을 바꿨습니다. 한 번에 하나의 구성요소만 제거해보고, 그것이 최종 결과에 어떤 영향을 주는지 검토하는 식이었습니다.
이런 반복을 돌리는 동안 Anthropic은 Opus 4.6도 출시했고, 이는 harness 복잡도를 줄일 또 다른 동기가 됐습니다. Opus 4.6은 4.5보다 적은 스캐폴드만으로도 더 잘 작동할 것이라 기대할 만한 이유가 충분했습니다. 출시 글에 따르면 "[Opus 4.6]은 더 신중하게 계획하고, agentic task를 더 오래 유지하며, 더 큰 코드베이스에서도 더 안정적으로 작동하고, 자신의 실수를 잡아내기 위한 코드 리뷰 및 디버깅 능력도 더 좋아졌습니다." 긴 context에서의 정보 검색 성능도 크게 향상됐습니다. 이런 능력들은 모두 기존 harness가 보완하려고 만들어 넣었던 것들입니다.
Removing the sprint construct
저는 먼저 sprint 구조를 완전히 제거했습니다. sprint 구조는 작업을 모델이 일관되게 처리할 수 있는 덩어리로 나누는 데 도움을 줬습니다. 하지만 Opus 4.6의 개선을 고려하면, 이제는 이런 분해 없이도 모델이 원래 작업을 직접 처리할 수 있을 것이라 기대할 근거가 충분했습니다.
planner와 evaluator는 그대로 유지했습니다. 둘 다 여전히 분명한 가치를 더했기 때문입니다. planner가 없으면 generator는 범위를 너무 좁게 잡았습니다. 원래 프롬프트만 주면 먼저 명세를 세우지 않은 채 바로 만들기 시작했고, 결과적으로 planner를 쓴 경우보다 기능이 훨씬 빈약한 앱을 만들곤 했습니다.
sprint 구조를 제거한 뒤에는 evaluator를 sprint별 채점자가 아니라 실행이 끝난 뒤 한 번만 검사하는 역할로 옮겼습니다. 모델 자체가 훨씬 더 강력해졌기 때문에, 어떤 실행에서는 evaluator가 실제로 얼마나 핵심적인 역할을 하는지도 달라졌습니다. 기준은 그 작업이 현재 모델이 혼자서 안정적으로 처리할 수 있는 경계의 안쪽인지 바깥쪽인지에 달려 있었습니다. 4.5에서는 그 경계가 꽤 가까웠습니다. 당시 빌드는 generator가 혼자서 잘 처리할 수 있는 한계 바로 근처에 있었고, evaluator는 전체 빌드에 걸쳐 의미 있는 문제를 잡아냈습니다. 반면 4.6에서는 모델 자체 역량이 올라가면서 그 경계가 바깥으로 이동했습니다. 이전에는 evaluator 점검이 있어야 일관되게 구현되던 작업도 이제는 generator가 혼자서 잘 처리하는 경우가 많아졌고, 그런 작업에서는 evaluator가 단지 추가 오버헤드가 되었습니다. 하지만 여전히 generator 역량의 경계에 걸쳐 있는 부분에서는 evaluator가 확실한 향상을 제공했습니다.
실무적으로 보면 evaluator는 고정된 예/아니오 판단 대상이 아닙니다. 작업이 현재 모델이 혼자서는 안정적으로 처리하지 못하는 범위에 있을 때, 그 비용을 들일 가치가 생깁니다.
구조 단순화와 함께 저는 각 앱에 AI 기능을 심는 방식을 개선하는 프롬프팅도 추가했습니다. 특히 generator가 도구를 통해 앱 자신의 기능을 구동할 수 있는 제대로 된 agent를 만들게 하는 방향이었습니다. 관련 지식이 꽤 최근이라 Claude의 학습 데이터에 충분히 반영되지 않았기 때문에, 이 부분도 실제로는 여러 차례 반복이 필요했습니다. 하지만 충분히 튜닝하자 generator는 agent를 올바르게 구축하기 시작했습니다.
Results from the updated harness
업데이트된 harness를 시험하기 위해 저는 아래 프롬프트로 Digital Audio Workstation(DAW), 즉 곡을 작곡하고 녹음하고 믹싱하는 음악 제작 프로그램을 만들게 했습니다.
Build a fully featured DAW in the browser using the Web Audio API.
이 실행 역시 여전히 길고 비쌌습니다. 대략 4시간이 걸렸고 token 비용은 $124 정도였습니다.
시간의 대부분은 빌더가 사용했습니다. Opus 4.5에서는 필요했던 sprint 분해 없이도 2시간 넘게 일관된 실행을 이어갔습니다.
| Agent & Phase | Duration | Cost |
|---|---|---|
| Planner | 4.7 min | $0.46 |
| Build (Round 1) | 2 hr 7 min | $71.08 |
| QA (Round 1) | 8.8 min | $3.24 |
| Build (Round 2) | 1 hr 2 min | $36.89 |
| QA (Round 2) | 6.8 min | $3.09 |
| Build (Round 3) | 10.9 min | $5.88 |
| QA (Round 3) | 9.6 min | $4.06 |
| Total V2 Harness | 3 hr 50 min | $124.70 |
이전 harness와 마찬가지로 planner는 한 줄짜리 프롬프트를 완전한 명세로 확장했습니다. 로그를 보면 generator 모델이 앱과 agent 설계를 잘 계획하고, agent를 연결하고, QA에 넘기기 전에 테스트까지 수행했다는 점을 확인할 수 있었습니다.
다만 QA agent는 여전히 실제 공백을 잡아냈습니다. 1차 피드백에서 QA는 이렇게 지적했습니다.
이 앱은 디자인 충실도가 높고 AI 에이전트도 탄탄하며 백엔드도 좋습니다. 하지만 가장 큰 실패 지점은
Feature Completeness입니다. 앱은 인상적이고 AI 통합도 잘 작동하지만, DAW 핵심 기능 몇 가지가 상호작용 깊이 없이 표시만 되는 상태입니다. 예를 들어 타임라인에서 클립을 드래그하거나 이동할 수 없고, 악기 UI 패널(신스 노브, 드럼 패드)도 없으며, 시각적인 이펙트 편집기(EQ 곡선, compressor meter)도 없습니다.
이런 것은 예외 사례가 아니라 DAW를 실사용 가능하게 만드는 핵심 상호작용이며, 명세에도 분명히 요구된 내용입니다.
2차 피드백에서도 QA는 여러 기능상 공백을 다시 잡아냈습니다.
남아 있는 공백:
- 오디오 녹음은 여전히 스텁 수준입니다. 버튼은 토글되지만 마이크 캡처가 없습니다.
- 클립 가장자리 드래그에 의한 크기 조절과 클립 분할이 구현되지 않았습니다.
- 이펙트 시각화가 그래픽이 아니라 숫자 슬라이더 수준에 머물러 있습니다. EQ 곡선이 없습니다.
generator는 혼자 두면 여전히 세부를 놓치거나 기능을 스텁으로 남겨둘 수 있었고, QA는 그런 마지막 구간의 문제를 잡아 generator가 수정하게 만드는 데 분명한 가치를 더했습니다.
이 프롬프트를 기준으로 제가 기대한 것은 멜로디와 화성, 드럼 패턴을 만들고 이를 곡으로 배열하면서, 통합된 agent의 도움도 함께 받을 수 있는 프로그램이었습니다. 아래는 그 결과를 보여주는 영상입니다.
이 앱은 전문 음악 제작 프로그램과는 거리가 멀었고, agent의 작곡 능력도 아직 갈 길이 멀었습니다. 게다가 Claude는 실제로 소리를 들을 수 없기 때문에, 음악적 취향과 관련된 QA 피드백 루프는 그만큼 덜 효과적일 수밖에 없었습니다.
그럼에도 최종 앱에는 기능하는 음악 제작 프로그램의 핵심 조각이 모두 들어 있었습니다. 브라우저에서 돌아가는 어레인지먼트 뷰, 믹서, 트랜스포트가 있었고, 거기서 한 걸음 더 나아가 저는 프롬프트만으로 짧은 곡 스케치를 실제로 만들어볼 수 있었습니다. agent는 템포와 키를 설정하고, 멜로디를 깔고, 드럼 트랙을 만들고, 믹서 레벨을 조정하고, 리버브까지 추가했습니다. 곡 작성을 위한 핵심 구성 요소가 갖춰져 있었고, agent는 도구를 사용해 처음부터 끝까지 간단한 제작 과정을 자율적으로 밀고 갈 수 있었습니다. 아직 음정까지 완벽하다고 할 수는 없지만, 분명 그 방향으로 가고 있습니다.
What comes next
모델이 계속 좋아질수록, 더 오래 일하고 더 복잡한 작업도 처리할 수 있으리라고 대체로 기대할 수 있습니다. 어떤 경우에는 모델을 둘러싼 보조 구조가 시간이 지나며 덜 중요해질 것이고, 개발자는 다음 모델을 기다리기만 해도 일부 문제는 저절로 해결될 수 있습니다. 반면 모델이 더 좋아질수록, 기준선 상태의 모델이 해내는 범위를 넘어서는 복잡한 작업을 달성할 수 있는 harness를 개발할 여지도 더 넓어집니다.
이 점을 염두에 두면, 이번 작업에서 앞으로도 가져갈 만한 교훈이 몇 가지 있습니다. 먼저, 자신이 활용하는 모델을 직접 실험해보고, 현실적인 문제에서 나온 trace를 읽고, 원하는 결과를 내도록 성능을 튜닝하는 것은 언제나 좋은 습관입니다. 또 더 복잡한 작업에서는 task를 분해하고 문제의 각 측면에 특화된 agent를 붙이는 방식에서 추가적인 여지가 나오는 경우가 있습니다. 그리고 새로운 모델이 등장하면, 더 이상 성능을 떠받치지 않는 조각은 덜어내고, 이전에는 불가능했던 더 큰 능력을 실현할 새 조각은 추가하면서 harness를 다시 점검하는 것이 대체로 좋은 실천입니다.
이번 작업을 통해 저는 흥미로운 harness 조합의 공간이 모델이 좋아질수록 줄어드는 것이 아니라, 단지 이동할 뿐이라는 확신을 갖게 됐습니다. 결국 AI 엔지니어에게 흥미로운 일은 그다음의 새로운 조합을 계속 찾아내는 것입니다.
Acknowledgements
Mike Krieger, Michael Agaby, Justin Young, Jeremy Hadfield, David Hershey, Julius Tarng, Xiaoyi Zhang, Barry Zhang, Orowa Sidker, Michael Tingley, Ibrahim Madha, Martina Long, Canyon Robbins에게 이 작업에 대한 기여에 감사드립니다.
또 이 글의 방향을 다듬는 데 도움을 준 Jake Eaton, Alyssa Leonard, Stef Sequeira에게도 감사드립니다.
Appendix
planner agent가 생성한 계획의 예시는 아래와 같습니다.
RetroForge - 2D 레트로 게임 메이커
개요
RetroForge는 2D 레트로풍 비디오 게임을 설계하고 제작하기 위한 웹 기반 크리에이티브 스튜디오입니다. 고전 8비트와 16비트 게임 미학의 향수와 현대적이고 직관적인 편집 도구를 결합해, 취미 창작자부터 인디 개발자까지 누구나 전통적인 코드를 직접 작성하지 않고도 자신의 게임 아이디어를 구현할 수 있게 합니다.
플랫폼은 서로 통합된 네 가지 창작 모듈을 제공합니다. 게임 월드를 설계하는 타일 기반 레벨 에디터, 시각 자산을 만드는 픽셀 아트 스프라이트 에디터, 게임 로직을 정의하는 시각적 엔티티 행동 시스템, 실시간 게임플레이 테스트를 위한 즉시 실행 가능한 플레이 테스트 모드입니다. 여기에 Claude 기반 AI 지원을 전반에 녹여 넣어, 사용자가 자연어 상호작용으로 스프라이트를 생성하고, 레벨을 설계하고, 행동을 구성하도록 도와 창작 과정을 가속합니다.
RetroForge는 레트로 게임 미학을 좋아하지만 현대적 편의성도 원하는 창작자를 대상으로 합니다. 어린 시절의 플랫폼 게임, RPG, 액션 게임을 재현하든, 레트로 제약 안에서 완전히 새로운 경험을 발명하든, 사용자는 빠르게 프로토타입을 만들고 시각적으로 반복 개선하며 결과물을 다른 사람과 공유할 수 있습니다.
기능
1. 프로젝트 대시보드 및 관리
프로젝트 대시보드는 RetroForge의 모든 창작 작업을 위한 출발점입니다. 사용자는 새 프로젝트를 만들고, 진행 중인 작업으로 돌아가고, 각 프로젝트에 무엇이 들어 있는지 한눈에 파악할 수 있는 명확하고 정돈된 관리 방식을 필요로 합니다.
사용자 스토리: 사용자는 다음을 원합니다:
- 이름과 설명이 있는 새 게임 프로젝트를 만들어 게임 설계를 시작하고 싶다
- 프로젝트 이름, 마지막 수정 날짜, 썸네일 미리보기를 보여주는 시각 카드 형태로 기존 프로젝트를 모두 보고, 빠르게 찾아 이어서 작업하고 싶다
- 어떤 프로젝트든 열어 전체 게임 편집 작업 공간으로 들어가 내 게임을 작업하고 싶다
- 더 이상 필요 없는 프로젝트는 실수를 막는 확인 대화상자와 함께 삭제해 작업 공간을 정리하고 싶다
- 기존 프로젝트를 새 게임의 출발점으로 복제해 이전 작업을 재사용하고 싶다
프로젝트 데이터 모델: 각 프로젝트에는 다음이 포함됩니다:
프로젝트 메타데이터(이름, 설명, 생성/수정 시각)
캔버스 설정(해상도: 예: 256x224, 320x240, 160x144)
타일 크기 설정(8x8, 16x16, 32x32 픽셀)
색상 팔레트 선택
연관된 모든 스프라이트, 타일셋, 레벨, 엔티티 정의
...
Footnotes
-
이 글은 이미 한국어로 번역해 두었습니다. 장시간 실행 에이전트를 위한 효과적인 harness에서 읽을 수 있습니다. ↩ ↩2 ↩3
-
이 글도 한국어 번역본이 있습니다. AI 에이전트를 위한 효과적인 컨텍스트 엔지니어링에서 이어서 읽어보세요. ↩